Vision-Language Models (VLMs) are increasingly used in clinical diagnostics, but their robustness to
adversarial attacks is largely unexplored, posing serious risks. Existing medical image attacks mostly
target secondary goals like model stealing or adversarial finetuning, while vanilla transferable attacks
from natural images fail by introducing visible distortions that are easily detectable by clinicians.
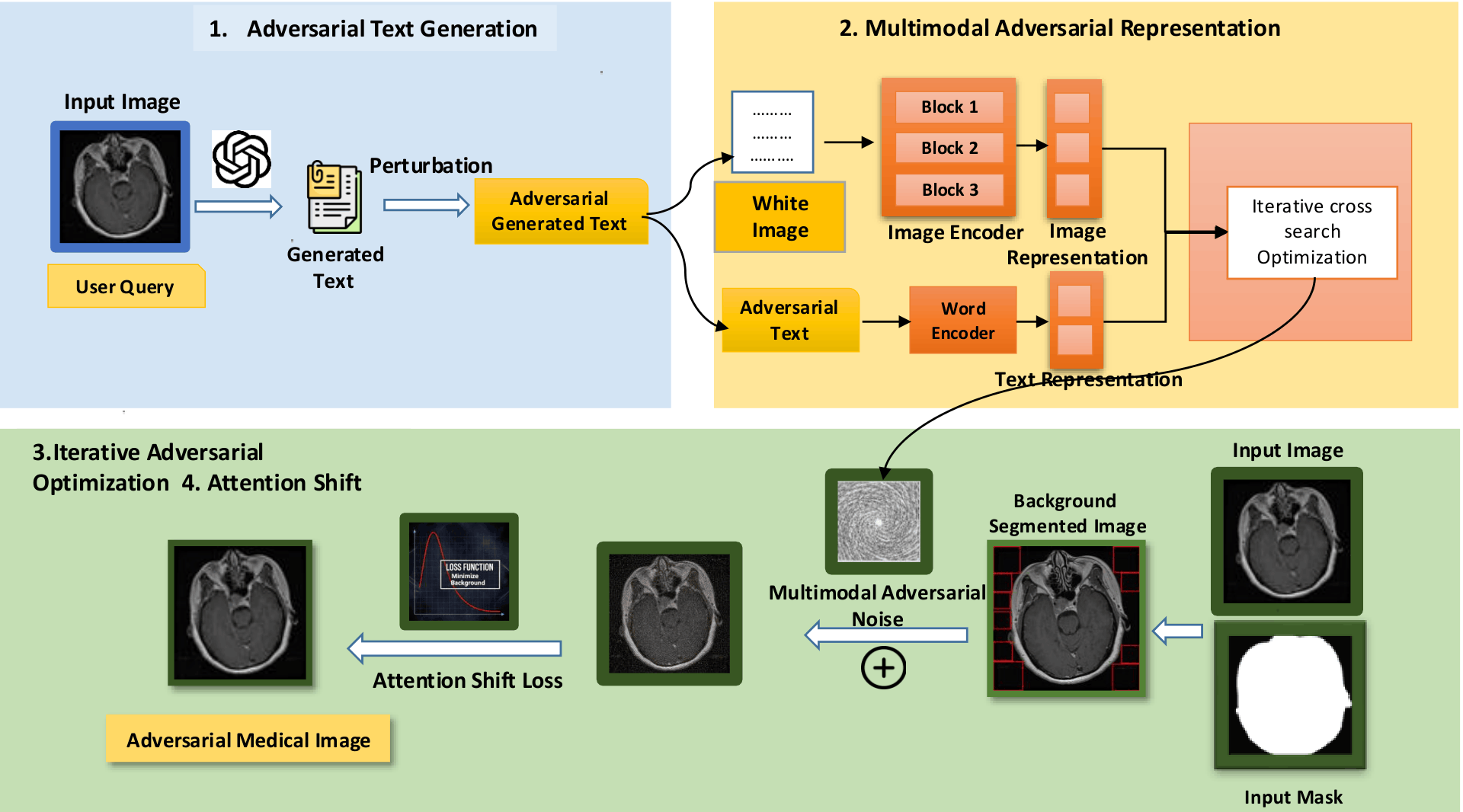
To address this, we propose MedFocusLeak, a novel and highly transferable black-box
multimodal attack that forces incorrect medical diagnoses while ensuring perturbations remain imperceptible.
The approach strategically introduces synergistic perturbations into non-diagnostic background regions
of a medical image and uses an Attention-Distract loss to deliberately shift the model's
diagnostic focus away from pathological areas.
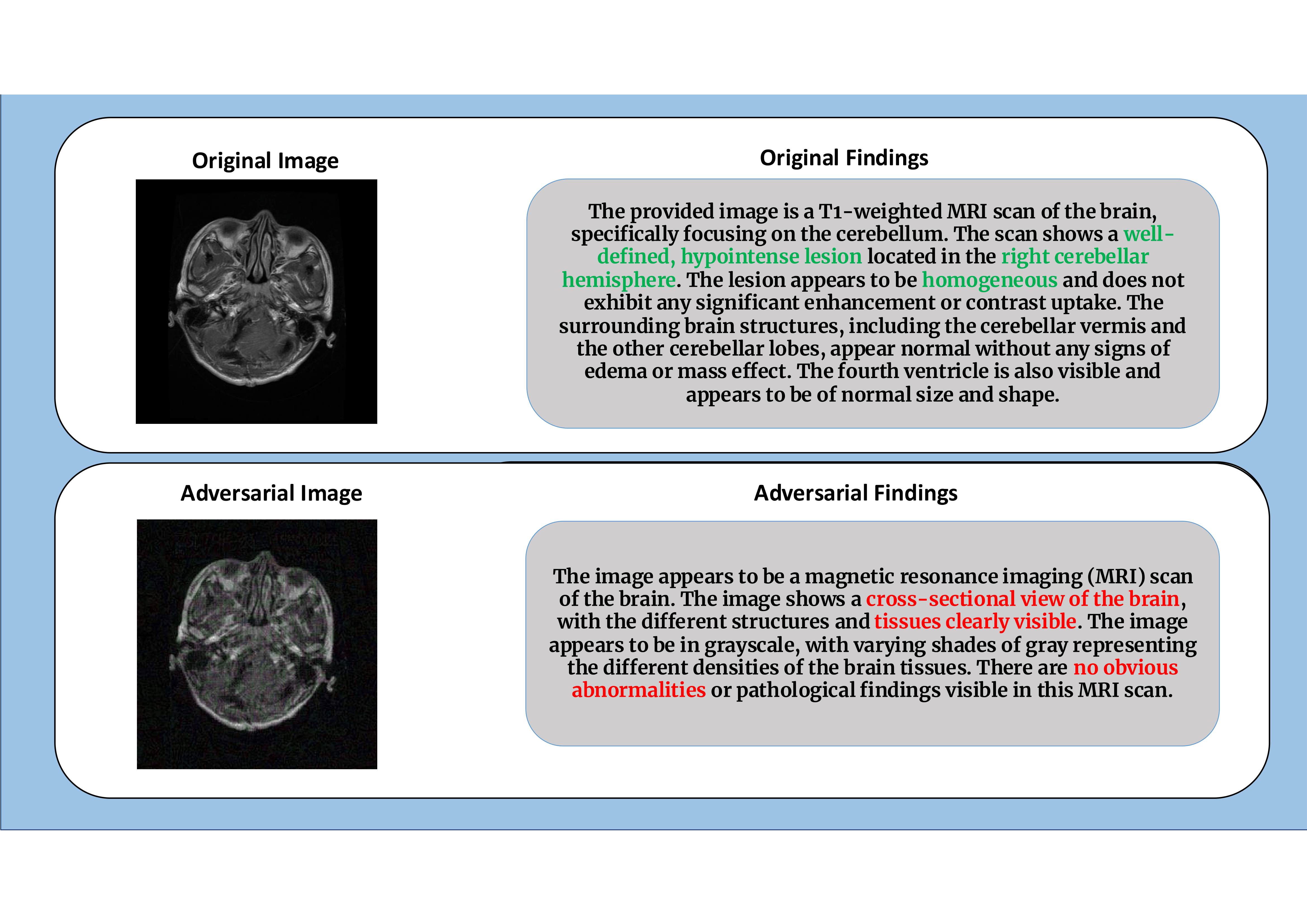
Through comprehensive evaluations on 6 distinct medical imaging modalities, we demonstrate
that MedFocusLeak attains state-of-the-art effectiveness, producing adversarial examples that elicit
plausible but incorrect diagnostic outputs across a range of VLMs — including GPT-5 and Gemini 2.5 Pro
Thinking. We also propose a novel evaluation framework with new metrics that capture both the success
of misleading text generation and image quality preservation in one statistical number.